本人能力有限,翻译只是为了更好的理解,如有错误欢迎指正!
本文翻译自《A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)》
1 决策树是什么?它是如何工作的?
决策树是一种监督学习算法(有预先定义的目标变量),并且经常被用在分类问题上。它既能用于分类变量也能用于连续变量。 在这个算法中,它将整体或样本基于输入变量中最显著的分类指标分成两个或多个同类子集。
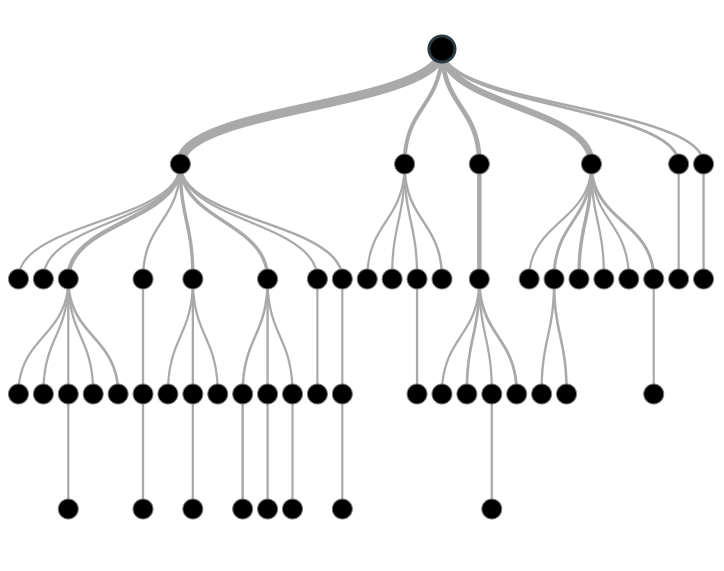
例子:
假设我们有三十位学生的数据,里面包含这些学生的性别,班级和身高。其中的15位学生在业余时间玩板球。现在,我想创建一个模型预测谁在 空闲时间玩板球。在这个问题中,我们需要根据三个变量中的显著变量来区分学生是否打板球。
决策树会根据全部变量对学生分类,并定义最能区分学生集合(不同的学生集合是异构的)的变量。从下面的图片可以看出,性别变量是将学生分成不同集合 (一个集合中大部分都喜欢板球,另一个集合反之)的最佳变量。
从上面可以看出,决策树定义给出最佳同类集合的显著变量,但问题是如何定义这个变量以及如何分离样本集合。下面我们将逐一讨论。
决策树种类
根据目标变量的种类分为两种决策树:
- 分类变量决策树:目标变量是分类变量的决策树模型是分类变量决策树。如上面的例子就是分类变量决策树。
- 连续变量决策树:目标变量是连续变量的决策树模型是连续变量决策树。
例子:当一个保险公司想知道顾客是否续约保费时,考虑到收入是一个非常重要的变量,但收入是未知的,这时候根据顾客的职业,购买产品和各种其他变量来构建决策树模型 来预测顾客的收入。在这个例子中,我们要预测的变量是连续变量。
关于决策树的重要术语
决策树的基础术语:
- 根结点:它代表整体或样本集合,它将分成两个或多个同类集合。
- 分裂:它表示一个结点分成两个或多个结点的过程。
- 决策结点: 当一个子结点进一步分裂成多个子结点,我们叫它决策结点。
- 叶结点/终端结点:当结点无法再继续分裂时称为叶结点。
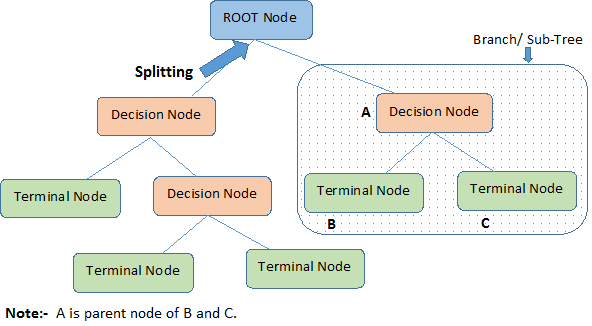
- 修剪:当我们去除决策结点的子结点时,这个过程叫做修剪。你可以称它为分裂的逆向。
- 子树/分支:一个树的完整的一部分叫做子树。
- 父结点和子结点:一个分裂成子结点的结点叫做子结点的父结点。
下面是决策树的优点和缺点:
优点:
- 易于理解:即使是没有统计背景的人也能容易的理解决策树的输出,它不需要统计知识去解释输出结果。它的图像展示非常直观,让使用者很容易的关联到他们的假设。
- 在数据探索中非常有用:决策树是用来定义显著变量和定义变量间关系的最快的方法之一。我们也可以用决策树创建新变量,你可以从这边文章学到如何应用。另外你也可以用 决策树来进行变量筛选。
- 更少的数据清洗需求:相对于其他模型决策树需要更少的数据清洗工作。在很大程度上决策树不会受到异常值和缺失值的影响。
- 数据类型不是一个限制:它既能处理数值变量也能处理分类变量。
- 非参数方法:决策树被认为是非参数方法,这意味着决策树没有关于空间分布和分类器结构的假设。
缺点:
- 过拟合:过拟合对决策树来说是一个最实际的难点。它可以通过设置模型参数和修剪来解决。
- 对连续变量不拟合:当处理连续变量时,在将变量分类到不同类别时它会失去一部分数据信息。
2.回归树VS分类树:
我们知道所有的终端结点都在决策树的底部,这意味着决策树是倒立的树形,如下图所示:

所有的树都是相似,让我们来看看他们主要的区别和相同之处:
- 当因变量是连续的我们使用回归树,当因变量是分类变量时我们使用分类树。
- 在回归树中,从训练集中的终端结点获取的数据是根据观测值的平均值来分类的。因此,如果一个不可见的观测数据分到某个区域,回归树是用均值做的预测。
- 在分类树中,从训练集中的终端结点获取的数据是根据观测值的众数来分类的。因此,如果一个不可见的观测数据分到某个区域,分类树是用众数做的预测。
- 所有的树都是把预测空间分成不同和不重叠的区域,为了简单起见,你可以把这些区域想象成不同维度的一个个箱子。
- 所有的树都是自顶向下的贪婪进程,被称作递归二元分裂。我们称它为自顶向下是因为一开始所有的数据是一个区域然后分裂成两个新的区域。称作贪婪是因为 算法只考虑当前的分裂过程,不考虑当前较差的分裂可能在以后的分裂中形成更好的树的情形。
- 分裂过程直到遇到终止条件才结束。例如,我们可以设置当每个结点的观测数据少于50时停止分裂。
- 在这两种算法中,分裂过程都是遇到停止条件进而形成完全成长的树。但是完全长成的树可能过拟合的,会导致算法在真实预测数据有很低的准确度。因此我们会使用修剪来处理过拟合。
3. 树如何决定在哪里分裂?
树的分裂算法非常影响树的准确度,分类树和回归树的决策标准不同。
决策树使用多种算法来决定一个结点的分裂,子结点的创建能提高所得结点的同质性。换句话说,此结点关于目标变量的纯度得到提高(更趋同)。决策树分裂根据所有的变量分裂结点,然后选择 分裂所得子结点同质性性最好的变量作为分裂变量。
根据目标变量的类型选择算法,下面我们看看最常用的几种算法。
Gini Index(基尼系数)
基尼系数,如果我们从整体随机选取两个观测数据,如果整体是纯粹的,它们属于同类的概率为1 。
- 它只应用于目标变量是分类变量(1 or 0)的数据。
- 它只应用于二元分裂。
- 基尼系数越高表示同质性越高。
- CART(分裂和回归树)使用基尼系数来进行二元分裂。
单个分裂的基尼系数计算步骤
- 使用事件成功或失败的概率平方的累加来计算子结点的基尼系数(p^2+q^2)。
- 使用每个结点的加权基尼系数来计算某次分裂的基尼系数。
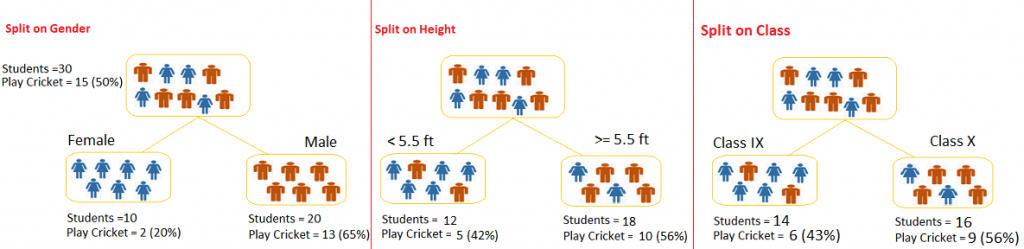
例子:我们使用上面学生是否玩板球的例子来计算基尼系数,我想看是关于性别分裂和班级分裂的基尼系数。
性别分裂:
- 计算女性结点的基尼系数:=(0.2)(0.2)+(0.8)(0.8)=0.68。
- 男性结点基尼系数:=(0.65)(0.65)+(0.35)(0.35)=0.55。
- 关于性别的加权基尼系数:=(10/30)0.68+(20/30)0.55=0.59。
班级分裂:
- IX的基尼系数:=(0.43)(0.43)+(0.57)(0.57)=0.51 。
- X的基尼系数:=(0.65)(0.65)+(0.35)(0.35)=0.55 。
- 班级的加权基尼系数=(10/30)0.51 + (16/30)0.51 = 0.51 。
从上面可以看出性别变量的基尼系数更高,因此此次结点的分裂选择性别变量。
Chi-Square(卡方)
这个算法是用来发现子结点与父结点间差异的统计显著性。我们可以通过观测值与期望值差值的平方和来计算卡方值。
- 它能处理目标变量是分类变量的数据。
- 它能处理多元分裂。
- 卡方值越高,子结点与父结点间差异的统计显著性越高。
- 每个结点的卡方值具有固定的计算公式。
- 卡方值 = :((实际值-期望)^2/期望)^1/2。
- 它生成树叫做CHIAD(卡方自动交互检查)。
卡方值的计算步骤:
- 通过计算事件成功和失败的偏差(与期望值相减)来计算单个结点的卡方。
- 通过计算此次分裂的所有结点的卡方和来计算此次分裂的卡方。
例子:
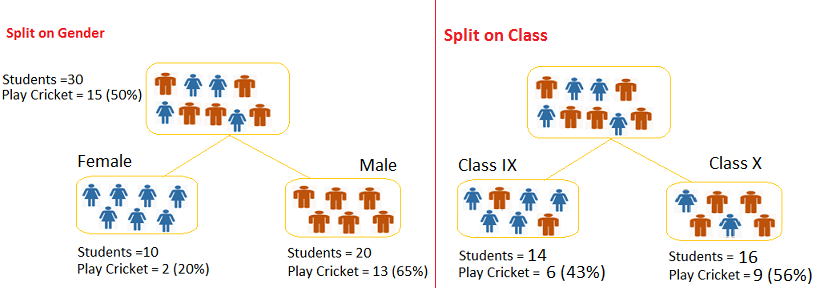
按性别分裂:
- 首先看女性结点,里面实际有2个学生玩板球,8个学生不玩板球。
- 计算玩板球和不玩板球的期望值,这里的期望值是5。因为整体数据中玩板球的概率是0.5,女性结点有10位学生,10*0.5=5。
- 用 真实值-期望值 来计算偏差。玩板球:(2-5=-3);不玩板球:(8-5=3)。
- 使用公式:((实际值-期望)^2/期望)^1/2计算女性结点中玩板球和不玩板球的卡方。
- 重复上面的步骤计算男性结点的卡方。
- 将所有的卡方值相加即得按性别分裂的卡方值。

按班级分裂:
按照上面相同的步骤计算班级分裂的卡方,如下表:

从上面可以看出按性别分裂比按班级分裂更加显著。
Information Gain(信息增益):
看下图中哪个结点更容易描述。你一定会选C结点,因为它需要更少的信息来描述,所以的值都是相似的。另一方面,B需要更多的信息来描述,
A需要最多的信息来描述。换句话说,C是一个纯粹的结点,B有少量的杂质,A是有最多的杂质。
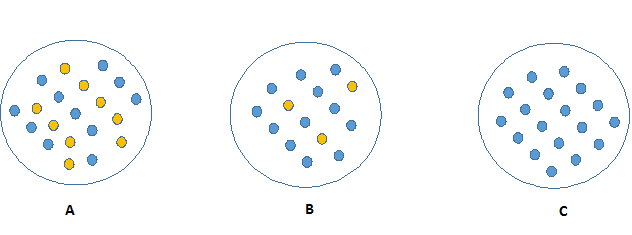
现在,我们得到一个结论杂质越少的结点需要越少的信息来描述,杂质多的结点需要更多的信息来描述。信息理论是用来定义一个系统的混乱程度,通常用熵来表示。 如果一个样本是完全同质的,那么它的熵为0。如果一个样本由两种不同的数据组成,且各占50%,那么它的熵为1。
熵的计算公式为:

在这里p和q表示结点中事件成功或失败的概率。熵被用在目标变量是分类变量的数据。它选择熵值最小的分裂,熵越小,分裂的越好。
分裂中熵的计算步骤:
- 计算父结点的熵。
- 计算分裂中所有结点的熵,并计算这些熵的加权平局值。
例子:与上面方法使用同样的数据样本
- 父结点的熵:=-(15/30)log2(15/30)-(15/30)log2(15/30)=1, 1表示此结点无杂质。
- 女性结点的熵:=-(2/10)log2(2/10)-(8/10)log2(8/10)=0.72,男性结点的熵:=-(13/20)log2(13/20)-(7/20)log2(7/20)=0.93。
- 性别分裂的熵:=子结点熵的加权平均值=(10/30)0.72+(20/30)0.93=0.86。
- IX结点的熵:=-(6/14)log2(6/14)-(8/14)log2(8/14)=0.99,X结点的熵:=-(9/16)log2(9/16)-(7/16)log2(7/16)=0.99。
- 班级分裂的熵:=(14/30)0.99+(16/30)0.99=0.99。
从上面可以看出性别分裂的熵最低,所以我们选择用性别变量来分裂。信息增益可以用(1-熵)得出。
Reduction in Variance(减少方差)
上面我们讨论了目标变量是分类变量的算法。减少方差是应用在目标变量是连续变量的数据(回归问题)。这个算法使用方差的标准公式来选择最好的分裂。
将分裂中方差最小的分裂作为分裂整体的标准:
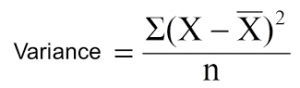
X-bar是均值,X是实际值,n是实际值的数目。
计算方差的步骤
- 计算每个结点的方差。
- 计算分裂中所有结点方差的加权平均值。
例子:数值1表示玩板球,数值0表示不玩板球。
- 根结点的方差,均值是(151+150)/30=0.5,方差=(15(1-0.5)^2+15(0-0.5)^2)/30=0.25 .
- 女性结点的均值=(21+80)/10=0.2, 方差=(2(1-0.2)^2+8(0-0.2)^2)/10=0.16。
- 男性结点的均值=(131+70)/20=0.65, 方差=(13(1-0.65)^2+7(0-0.65)^2)/20=0.23。
- 性别分裂的方差=子结点的加权方差=(10/30)*0.16 + (20/30) *0.23 = 0.21。
- IX的均值= (61+80)/14=0.43,方差=(6(1-0.43)^2+8(0-0.43)^2)/14= 0.24。
- X的均值= (91+70)/16=0.56 ,方差=(9(1-0.56)^2+7(0-0.56)^2) / 16 = 0.25。
- 班级分裂的方差= (14/30)0.24+(16/30)0.25 = 0.25。
从上面可以看出按性别分裂方差更低,因此选择按性别分裂。
4.树模型的关键参数有哪些,在决策树中如何避免过拟合?
过拟合是决策树面临的最关键的挑战。如果对集合没有设置限制,在训练数据集上会出现100%的准确率,更糟糕的情况是每个观测值都被当做一个子集(成为决策树的终端结点)。 这里有两种方法来避免过拟合:
- 对树的尺寸设置限制。
- 对树进行修剪。
对树的尺寸设置限制
可以通过设置定义树的各种参数来对树的尺寸做限制,下面是一棵决策树的一般结构:
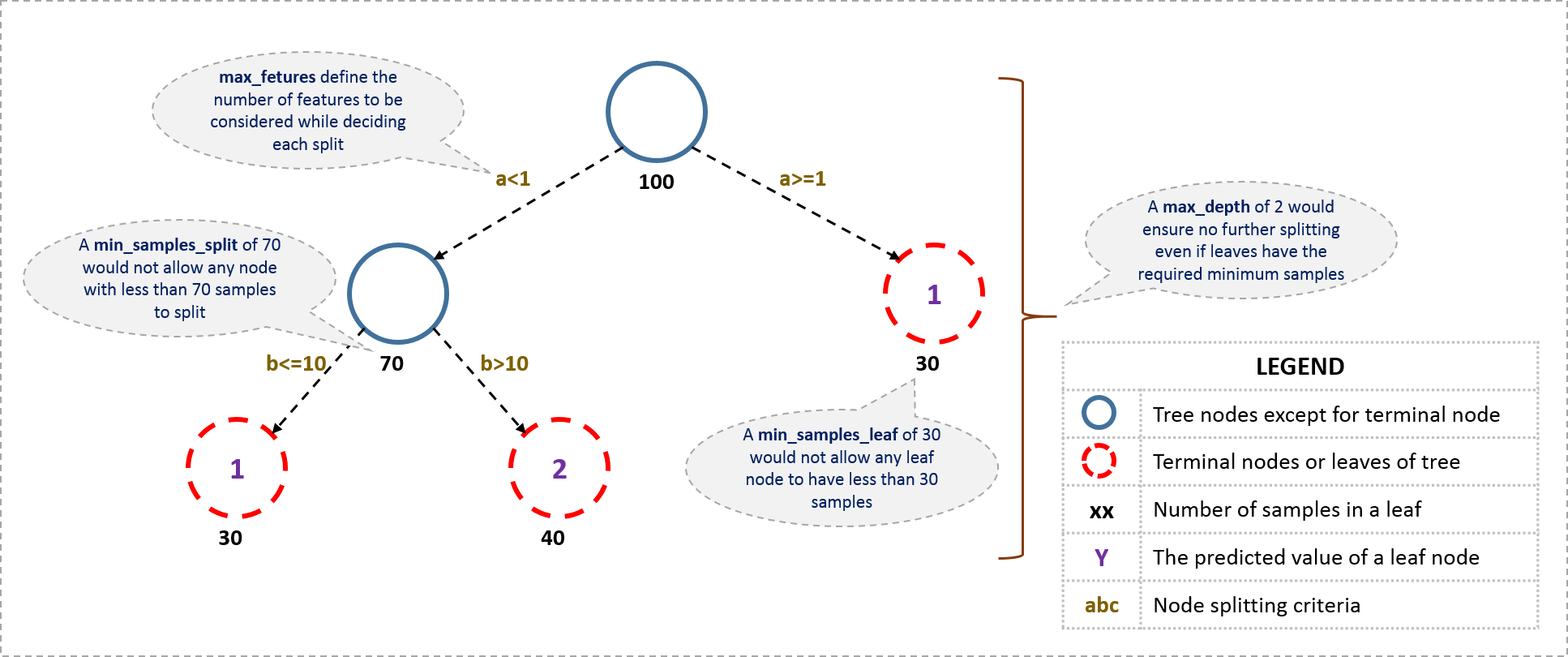
关于树的参数的进一步解释如下。下面的参数描述没有区分工具(R,python等),重要的是理解参数在树模型中意义。
- 结点分裂的最小样本数
- 定义一个结点能够继续分裂的最小样本数。
- 用来控制过拟合。高值可以避免一个模型在某个特殊样本中学习到过于具体的分类(例如上文提到的一个观测值一个子集)。
- 太高的值会导致欠拟合,因此需要通过交叉验证来调整。
- 终端结点的最小样本数
- 定义终端结点的最小样本数。
- 和 1 相似,用来控制过拟合。
- 通常对于不平衡问题选择较小的值,因为在少数类所占的区域样本数会比较小。
- 树的最大深度
- 树的最大深度。
- 用来控制过拟合,过高的值可能会使一个模型在某个特殊样本中学习到过于具体的分类(例如上文提到的一个观测值一个子集)。?
- 应该通过交叉验证来调整。
- 终端结点的最大样本数
- 终端结点的最大样本数
- 可以代替树的最大深度。因为一棵二分树的创建,n度的树会产生最多2^n个叶子。
- 作为分裂的最大特征数
- 能够用来分裂的最大特征数,这些特征是随机选择的。
- 作为经验,特征总数的平方根能够很好的工作,但是我们应该检查特征总数30%到40%。
- 过高的值可能会导致过拟合,但要根据具体的例子来选择。
树的修剪
像之前讨论的,设置约束的技术是一个贪婪的进程。换句话说,它检查当前最佳分裂并向前进行,直到遇到指定的停止条件。让我们考虑下面的例子:
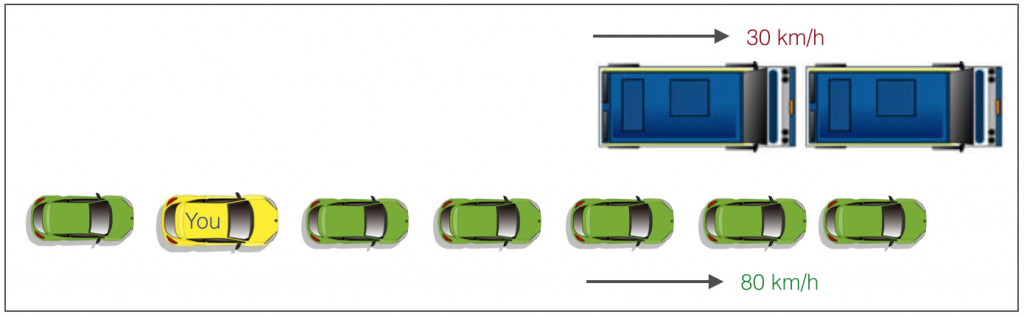
这里有两条车道:
- 一条车道,汽车以80km/h的速度前进。
- 一条车道,卡车以30km/h的速度前进。
现在,你是那个黄色的车并有两个选择:
- 向左转并超过前面的两辆汽车。
- 继续在目前的车道前进。
分析这两个选择。第一个选择,你立刻超过两辆汽车,并跟在卡车后以30km/h的速度前进,然后寻找机会向右移动。同时所有原来在你后面的汽车向前继续行驶。 如果你想在后面十秒钟行进最大的距离,那么这是最优的选择。第二个选择,你继续保持80km/h,和卡车并行,在适当的情况超过卡车。
这就是正常决策树和修剪之间的区别。一个带约束的决策树不会看到前面的卡车,会采用贪婪进程向左转。另一方面如果我们使用修剪,我们实际上能提前看到卡车然后再作出选择。
所以我们知道修剪更好,但是如何在决策树中应用修剪呢?
- 我们首先设置一个较大的深度。
- 计算叶子结点从顶部到底部分裂过程的加和增益,删除那些加和增益是负的结点。
- 假设一个分裂使算法增益-10(损失10的信息),下一步分裂增益20.一个简单的决策树会在第一次分裂停止然后进行修剪,我们将会看到决策树整体增益为10并保留所有的叶子。
注意python中的 sklearn并不支持修剪,R中的rpart包支持修剪。
5. 树模型比线性模型更优吗?
我们需要根据的实际的问题类型选择算法,下面是一些选择算法的关键因素:
- 如果因变量和自变量能够被线下模型很好的拟合,线性模型会表现的比树模型好。
- 如果因变量和自变量间的关系是非线性的,树模型比传统的回归模型表现的更好。
- 如果你需要创建一个对人们更容易的模型,决策树会是很好的选择。决策树比线性模型更容易解释。
6. 使用R 和Python 构建决策树
在R中有ctree,rpart,tree等包来构建决策树。
在R中有ctree,rpart,tree等包来构建决策树。
library(rpart)
x <- cbind(x_train,y_train)
grow tree
fit <- rpart(y_train ~ ., data = x,method=”class”)
summary(fit)
Predict Output
predicted= predict(fit,x_test)
在上面的代码中:
- y_train 表示因变量。
- x_train 表示自变量。
- x 表示训练集。
Python代码:
Import Library
Import other necessary libraries like pandas, numpy…
from sklearn import tree
Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
Create tree object
model = tree.DecisionTreeClassifier(criterion=’gini’) # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
model = tree.DecisionTreeRegressor() for regression
Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
Predict Output
predicted= model.predict(x_test)
7. 基于树建模的集成方法是什么?
集成模型是聚合多个预测模型来达到一个更好的准确度并使模型更加稳定。集成模型是对基于树的模型添加supreme boost。
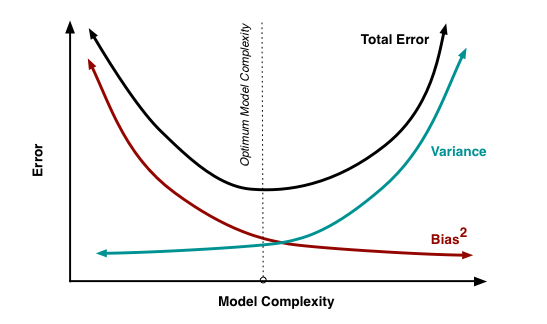
像其他模型一样,树模型也会出现偏差和方差的问题。偏差的意思是:实际值与预测值的平均差距(更多的是描述不同算法对数据的影响)。方差的意思是从整体中选取的不同样本在相同模型下同一点处表现出的差异。
如果你建立一棵低方差高偏差的树模型,你如何平衡偏差和方差间的大小关系?
通常,当你增加模型的复杂度,由于模型的低偏差你会看到预测误差变小。当你继续增加模型的复杂度,直到你的模型过拟合,这时你的模型会出现高方差。
一个成功的模型应该保持偏差和方差间的平衡。集成模型是一种执行方差偏差权衡分析的方法。
通常使用的集成方法包括:bagging, boosting 和 stacking。
8. bagging是什么?它是如何工作的?
bagging是一种在相同数据集下不同的子集应用多个分类模型,并结合全部的分类结果来减少预测方差的一种技术。下面的图片解释的更清晰。
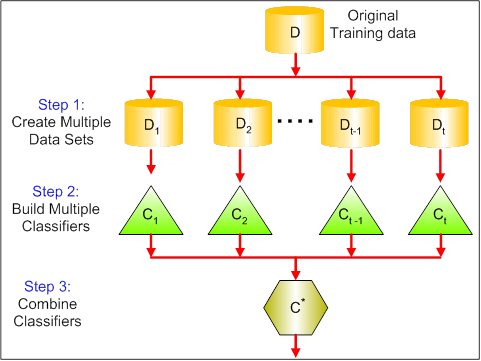
bagging的步骤:
- 创建多个数据集:
- 在原始数据集执行可放回的抽样,形成多个新的数据集。
- 新数据集可能有行和列的一部分,行和列的数目一般是bagging模型中的超参数。
- 行大于列能使模型鲁棒性更高,也更不容易出现过拟合。
- 创建多个分类模型:
- 每个数据集创建一个分类器。
- 通常在每个数据集上建立相同的模型,并进行预测。
- 合并分类器:
- 根据实际问题使用均值,中位数,众数来合并所有分类器的预测。
- 合并值通常比单一模型具有更好的鲁棒性。
注意,建立模型的数目不是一个超参数。模型的数目越高,模型的效果越好(或与低数目模型相似)。在某些假设下,它能理论上证明合并预测的方差是原始方差的1/n。
随机森林是应用bangging模型的一个例子。
9. 随机森林是什么?它是如何工作的?
随机森林是一个万能算法,一个小玩笑,当你不知道用什么算法时,使用随机森林。
随机森林能够应用在回归和分类问题上。它同时也能很好的处理数据降维,异常值和其他数据探索的过程。它是一个将多个弱模型合并成一个强模型的集成模型。
它是如何工作的?
在随机森林中我们生成多棵树而不是像在CART中只生成一棵。为了基于属性分类新对象,每棵树进行一个分类,我们称这棵树为此类的投票。随机森林选择最多投票数的分类。在回归分类中,我们采用不同树输出的平均值作为分类。
随机森林的每棵树以如下的方式运行:
- 对训练集进行可放回抽样,抽样结果将成为新的训练集并生成一棵树。
- 如果这里有M个输入变量,每个结点的数目m一定小于M。m是从M中随机选择的。m上最佳分裂被用来分裂此结点,在树的生成过程中m值固定不变。
- 每棵树都尽可能的扩展,并且不做修剪。
- 聚合所有树的预测来预测新数据。
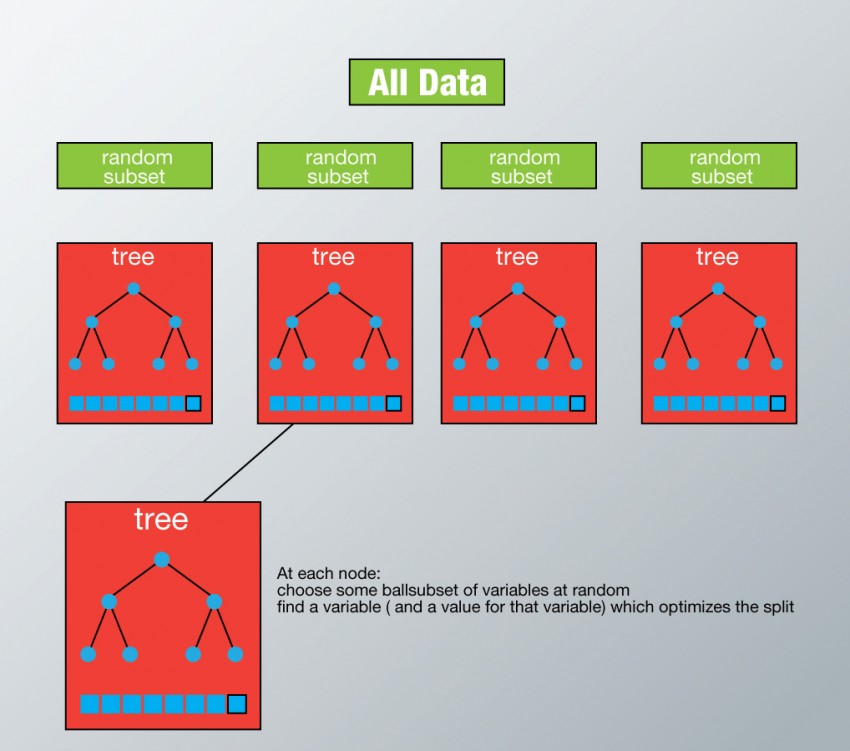
为了更好的理解随机森林,请阅读.
随机森林的优势
- 这个算法能够用于分类变量和回归变量,并能在两方面做一个比较好的估计。
- 随机森林能处理高纬度的大数据集。它能处理数以千计的变量并定义最显著的变量,所有它也是一种特征选择的方法。更进一步,它能输出最重要的变量。
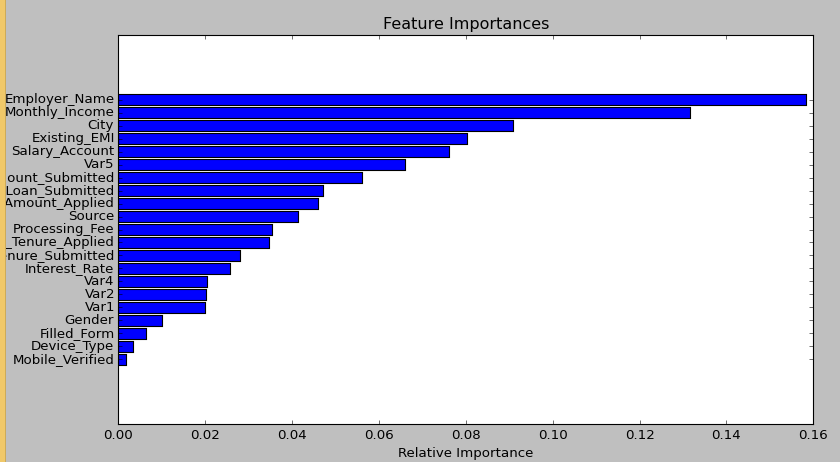
- 它是估计缺失值的有效的方法。当大部分数据缺失时,能保持一个比较好的准确度。
- 它也能处理不平衡数据集。
- 上面那些方法也能扩展到非标记数据,可以进行无监督聚类,数据视图和异常值检测。
- 随机森林采用可放回抽样,称为bootstrap 采样。其中有三分之一的数据用来做测试集。这些叫做the out of bag samples。错误估计在the out of bag samples上被叫做the out of bag 误差。
随机森林的劣势
- 它能在分类问题中取得较好的结果,但在回归问题中不能给出精确的连续预测。在回归问题中,它不能预测超出训练集的范围,并且由于特殊的噪音可能会造成过拟合。
- 随机森林对于建模者是一个黑箱子,你只能控制模型的一小部分。你最多只能尝试不同的参数和随机种子。
R & python
python
Import Library
from sklearn.ensemble import RandomForestClassifier #use RandomForestRegressor for regression problem
Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
Create Random Forest object
model= RandomForestClassifier(n_estimators=1000)
Train the model using the training sets and check score
model.fit(X, y)
Predict Output
predicted= model.predict(x_test)
R 代码
library(randomForest)
x <- cbind(x_train,y_train)
Fitting model
fit <- randomForest(Species ~ ., x,ntree=500)
summary(fit)
Predict Output
predicted= predict(fit,x_test)
10. boosting是什么?它是如何工作的?
定义:boosting和一系列将弱学习者转换为强学习者的算法有关。
如何区分一个邮件是垃圾邮件,我们用下面的准则定义一个邮件是否是垃圾邮件:
- 邮件只有一个图片,它是垃圾邮件。
- 邮件只有链接,它是垃圾邮件。
- 邮件的主体的句子中包含‘你赢得xx’。它是一个垃圾邮件。
- 邮件的来源是‘xx’。不是垃圾邮件。
- 邮件的来源是已知。不是垃圾邮件。
上面,我们定义了多种规则去分类一个邮件是否是垃圾邮件。但是这些规则不能成功的区分垃圾邮件。
单独的这些规则无法有效区分垃圾邮件。因此,这些规则是弱学习者。
为了将弱学习者转换为强学习者,我们用下面的方法合并每个弱学习者的预测:
- 使用加权平均或均值
- 考虑有更高投票的预测
例如,某个邮件,上面5个弱学习者,3个投票给垃圾邮件,2个投票给非垃圾邮件,在这个例子中,我们认为这个邮件是垃圾邮件,因为垃圾邮件获得了三票。
它是如何工作的?
现在我们知道,boosting合并弱学习者,即基础的学习者来形成一个强规则。一个问题立刻在脑海中涌现‘boosting如何定义弱规则’?
为了去发现弱规则, 我们应用具有不同分布的基础学习算法。每次应用基础学习算法,便产生一个弱规则。这是一个迭代的进程。在多次迭代后,boosting算法将这些弱规则合并成一个强规则。
这会产生另一个问题:在每轮迭代中我们如何选择不同的分布?
为了选择正确的分布,我们进行如下步骤:
步骤1:基础的学习者采用所有的分布,并对每个观测提供相同的权重。
步骤2:如果第一次基础学习算法没有产生任何预测误差,那么我们将注意力放到产生预测误差的变量上。然后我们应用下一个基础学习算法。
步骤3:迭代步骤2,直到达到最高的准确度或基础学习算法的极限。
最后它合并所有的弱学习者的输出并创建一个强学习者来提高模型的预测。Boosting将注意力更多的放在了产生错误分类或预测误差的弱规则上。
11. 哪个模型更好? GBM 还是 XGBOOST?
作者倾向于使用XGBOOST,下面列举了XGBOOST优于GBM的地方:
- 正则化:
- 标准的GBM没有正则化,但是XGBOOST有,因此它可以减少过拟合。
- 事实上,XGBOOST以它的‘regularized boosting’技术而出名。
- 并行计算:
- XGBOOST采用并行计算,要比GBM快很多。
- 但等一下,我们知道boosting是顺序过程,我们要如何并行计算呢?我们知道只有前一棵树创建后才能创建下一棵,所以我们可以对单棵树多核计算。这里有进一步的阐述。
- XGBOOST支持在HADOOP上的并行计算。
- 高度的灵活性
- XGBOOST允许我们自定义优化目标和评估标准。
- 模型添加了一个全新的视角,但并没有限制我们的任何操作。
- 处理缺失值
- XGBOOST内建程序来处理缺失值。
- 用户需要提供一个与观测值不同的值,作为参数传递给模型。当遇到缺失值时,XGBOOST尝试不同的方法并进行学习然后选择合适的方法处理缺失值。
- 树的修剪
- 当某个结点返回一个负面的损失时,GBM停止分裂,因此GBM是一个贪婪算法。
- XGBOOST是达到指定最大深度,然后向后修剪,去除那些没有正增益的分裂。
- 另一个优势是有时第一次分裂产生-2的增益,第二次分裂产生+10的增益,GBM会在第一次分裂停止,XGBOOST会保持分裂得到一个+8的整体增益。
- 内建交叉验证
- XGBOOST允许使用者在boosting进程的每次迭代都使用一个交叉验证,因此在一个单独的运行中非常容易获取boosting的最佳数目。
- GBM只能使用grid-search搜索参数,并且只能测试有限的参数值。
- 继续处理现有的模型
- 用户可以训练上一次迭代得到XGBOOST模型。这在某些特殊应用中会成为一个显著的优势。
- sklearn上的GBM应用同样具有这个性质。
12.在R和python上运行GBM
下面是二元分类的GBM伪代码:
- 初始化结果
- 从1开始迭代到最大数目的树
- 依据前一次模型更新目标变量的权重(哪一类错误分类更高)
- 选取子集训练模型
- 在全局上做预测
- 根据当前的结果更新输出,同时考虑调整学习率
- 得到最终结果
上面非常简单的解释了GBM的工作原理。
下面是在PYTHON中GBM的重要参数:
- learning_rate(学习率)
- 它对每棵树的最终结果都有影响。GBM使用每棵树的结果来更新初始估计。学习率在模型估计中控制着每次变化的大小。
- 一般选择更低值,因为它使模型对具有特殊特征的树更具鲁棒性。
- 更低的值代表更多次的迭代,会非常消耗计算。
- n_estimators
- 需要建模的树的数目(上面的步骤2)。
- 尽管GBM在具有更高迭代数上有很好的鲁棒性,但在某一点还是可能会出现过拟合。因此,这个参数应该在特定的学习率下用交叉验证来调整。
- subsample
- 每棵树的被选择的观测值的数目。通过随机抽样选择观测值的数目。
- 值小于1可以减少方差和增强模型的鲁棒性。
- 一般0.8能很好的工作但你可以根据实际进行调整。 除了上面这些参数,还有一些其他参数影响整体模型的表现:
- loss
- 它指每次分裂中需要进行最小化的损失函数。
- 对于分类和回归它可能是各种的值(例如class: deviance / exponential等)。一般默认值就能取得很好的表现。如果你能理解loss对模型的影响你可以选择其他的值。
- init
- 这个参数影响输出的初始化。
- 如果我们使用另一个模型的输出作为GBM的初始估计可以使用这个参数。
- random_state
- 每次生成的随机数。
- 它对参数调整很重要。如果我们不固定随机数,那么同样参数下后续运行的每次结果都会不同,我们将无法比较模型。
- 对某一特别的随机样本可能会出现过拟合。我们虽然可以尝试在不同的样本集上运行模型,但计算耗时,一般不会使用。
- verbose
- 模型拟合的输出类型:
- 0:无输出(系统默认)
- 1:在某些间隔输出树的结果
- 大于1: 输出所有树的结果
- 模型拟合的输出类型:
- warm_start
- 这个参数有一个很有意思的应用,如果能正确使用可以给使用者很多帮助。
- 使用这个参数,我们可以在先前适合的模型上拟合额外的树。它能节省很多时间,你应该探索它的高级应用。
- presort(预分类)
- 为了快速分裂可以选择是否预分类的数据
- 默认是自动选择的,如果有需要可以改变。
你能在这里找到一系列参数的列表,作者将它简化并放到了excel里。
对于R使用者,应用CARET包,主要考虑3个参数:
- n.trees。 它指迭代的数目。
- interaction.depth。 它指树的复杂度,例如一颗树总共分裂多少次。
- shrinkage。 它指学习率,和Python中学习率相似。
- n.minobsinnode。它只一个结点能够分裂的最小数目。
GBM在R中(带交叉验证)
使用者可以根据具体情况调整相关参数:
library(caret)
fitControl <- trainControl(method = “cv”, number = 10, #5folds)
tune_Grid <- expand.grid(interaction.depth = 2, n.trees = 500, shrinkage = 0.1, n.minobsinnode = 10)
set.seed(825)
fit <- train(y_train ~ ., data = train, method = “gbm”, trControl = fitControl, verbose = FALSE, tuneGrid = gbmGrid)
predicted= predict(fit,test,type= “prob”)[,2]
GBM在Python
import libraries
from sklearn.ensemble import GradientBoostingClassifier #For Classification
from sklearn.ensemble import GradientBoostingRegressor #For Regression
use GBM function
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1)
clf.fit(X_train, y_train)
13. 在R和Python中应用XGBOOST
XBGOOST采用并行计算比大多数的梯度提升算法快十倍,并且支持各种目标函数,包括回归,分类和排序。
利用R进行XGBOOST建模;Check Tutorial
利用Python进行XGBOOST建模;Check Tutorial