本人能力有限,翻译只是为了更好的理解,如有错误欢迎指正!
本文翻译自《A Comprehensive guide to Data Exploration》
数据探索和预处理的几个步骤:
数据的好坏往往能决定最后结果的好坏,所以一旦你的商业假设准备好了,花费一些时间去做数据的探索和预处理是值得的。根据作者的个人经验的估计,数据探索、清洗和预处理的时间能占到整个项目的 70%。
下面是为了构建预测模型需要对数据理解、清洗和预处理的几个步骤:
- 变量定义
- 单变量分析
- 双变量分析
- 缺失值处理
- 异常值处理
- 变量转换
- 变量创建
最后我们需要不断重重4-7步以得到我们的最终模型。
变量定义
首先,定义预测变量和目标变量,然后定义数据类型和变量的种类。
下面是一个例子:假设我们想预测学生是否玩板球(Play Cricket)。这里你需要定义预测变量、目标变量、变量的数据类型和数据种类
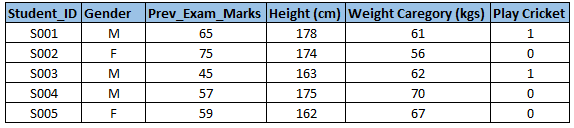
下面,变量被定义为不同的种类。
这里作者介绍的关于变量种类的定义比较简单,下面是我提取的数据挖掘导论中第二章中关于数据属性的部分内容:根据下文的“变量转换”中的内容,所有类型变量的数据类型都可以转为数值类型,我们根据这些数值变量具有的性质(或操作:相异性[=,!=],序[>,<],加减法,乘除)分类为:标称(nominal),序数(ordinal),区间(interval),比率(ratio)。
其中标称和序数又属于分类(或定性)变量,区间和比率属于数值(定量)变量,定量变量
可以是连续的也可以是离散的。如下表:

单变量分析
在这个阶段,我们探索每个变量。进行单变量分析的方法取决于变量的种类是分类的还是连续的
接下来,对分类变量和连续变量的分析方法和统计度量分别进行讨论。
连续变量:在连续变量的情况下,我们需要理解变量的集中趋势和分布。下面是将需要度量的统计指标可视化的方法。

注意:单变量分析也可以用来查找缺失值和异常值。
分类变量:对于分类变量,我们使用频数表来理解变量中每种类别的分布。我们也可以计算每种类型所占百分比。这里通常使用两个指标:计数和百分比。条形图也可以用来可视化分类变量,即纵轴为每种类型的计数。
双变量分析
双变量分析能找出两个变量间的关系。在一个预先定义的显著水平下查看变量间是否是连续的。
我们可以对分类变量和连续变量的任何组合进行双变量分析。这个组合可以是:分类&分类,分类&连续,连续&连续。在分析的进程中用不同的方法处理这些组合。
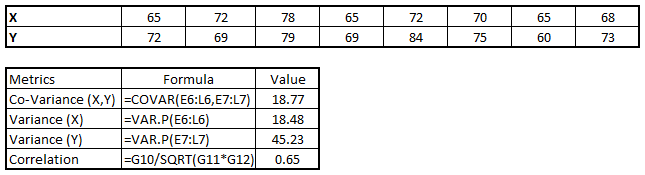
连续&连续:在对两个连续变量进行双变量分析时,我们需要查看它们的散点图。这是一个非常好的手段去发现两个变量的关系。散点图的模式显示了变量间的关系,它们可能是线性或非线性的。
散点图只展示了两个变量间关系,而不能显示变量间关系的强度。为了发现关系的强弱,我们用相关性来表示。相关性在 -1 到 1 之间。
- -1:完美的负相关
- +1:完美的正相关
- 0:不相关
相关性可以用下面的公示来计算:
Correlation = Covariance(X,Y) / SQRT( Var(X)* Var(Y))
在 excel 中可以用 CORREL()函数来计算相关性,在 SAS 中可以用 PROC CORR 来计算相关.
在R语言中可用cor(),cor.test(),corr.test()来计算。
分类&分类:为了发现两个分类变量间的关系,我们使用如下方法:
- 双向表(Two-way table):我们可以创建计数和百分比的双向表来分析其相关性。行表示一个变量的种类,列表示另一个变量的种类。我们展示每个行列种类组合的计数和百分比。
- 堆叠柱状图:这个方法更多是为了可视化双向表用的。

- 卡方检验:这个检验是用来得到变量间关系的统计学意义的方法。它也检验在这个样本得到变量的关系是否在总体(或更大的样本)中适用。卡方检验是基于双向表中类别观察频数和预期频数的差别来计算的。
通过计算卡方分布和其自由度得到一个相应的概率值。
概率值为0:表明所有的分类变量是相互依赖的。
概率值为1:表明所有的变量是独立的。
概率值小于0.05:它表明在 95%的置信区间,变量间的关系是显著的。检验两个分类变量独立性的卡方检验统计量为:
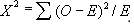
O 表示观察频数。E 表示 O 假设的期望频数,计算公式为:
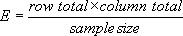
从前面的双向表,product category 1 成为 small size 的预期频率为 0.22。将small size 行的总数 和 product category 1 列的总数,以及样本总数带入上面的公式,可得到E。用来分析关系强弱的统计方法有:
Cramer’s V :无序类别变量
Mantel- - Haenszed Chi- - Square :有序类别变量
SAS:Chisq –>Proc freq
分类&连续:当探索分类变量和连续变量的关系时,可以为分类变量的每个水平画箱型图。如果各水平的观察频数很小,它将不能展现统计显著性。为了观察统计显著性,我们采用 Z-test, T-test or ANOVA。 - Z-Test/ T-Test:两个检验都能评估两组的均值是否有统计学差异。
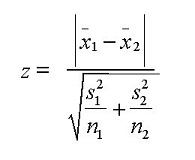
如果 Z 的概率值是小的,那么两均值的差别是显著的。T-test 和 Z-Test 很相似,但它通常用在两个类别的观察数目小于 30 的情况。

- 方差分析:它用来评估多组的均值是否有统计学差异。
例子:假设,我们想检测五个不同锻炼的作用。我们雇佣 20 个人,每种锻炼分配 4个人。在几周后记录他们的体重。 我们想知道这五中锻炼的作用是否有统计学差异。这个可以通过互相比较五组中每个人的体重得到。 到这,我们理解了数据探索的前三个步骤。变量定义、单变量分析、双变量分析。我们同时也了解了一些定义变量关系的统计手段和可视化方法。
现在,我们将要学习处理缺失值的方法。更重要的是我们还要学习缺失值出现的原因和处理缺失值必要性的原因。
缺失值处理
为什么需要处理缺失值?
训练集存在缺失值会减弱模型的拟合,还可能会产生一个有偏差的模型,因为我们没有正确分析缺失值和其他变量间的表现和关系。这可能导致一个错误的预测或分类。
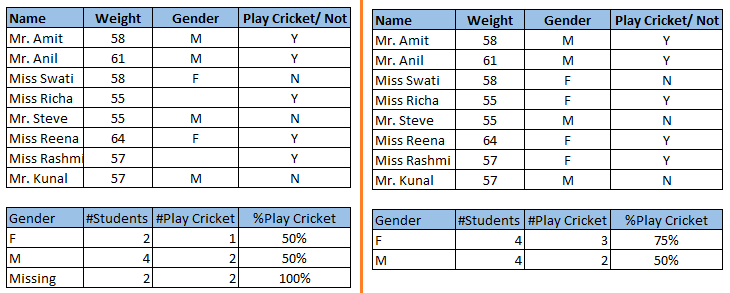 注意上面图片中的缺失值:在左边的场景,我们没有处理缺失值。从这个数据集可以推断男性玩板球的几率大于女孩。在另一方面,观察第二个表,在处理缺失值后女性玩板球的几率大于男性。
注意上面图片中的缺失值:在左边的场景,我们没有处理缺失值。从这个数据集可以推断男性玩板球的几率大于女孩。在另一方面,观察第二个表,在处理缺失值后女性玩板球的几率大于男性。
为什么我的数据有缺失值?
我们学习了在一个数据集中处理缺失值的重要性。现在我们来定义下出现缺失值的原因。它们可能出现在以下两个方面:
- 数据提取:数据提取是指数据使用者从数据平台(例如数据库)提取数据的过程。在这个过程可能由于sql语句中少写了几个判断条件而使数据产生缺失值,因此在数据提取过程中一定要确定好取数逻辑,并做一些必要的验证。在数据提取阶段出现错误是比较容易发现和解决的。
- 数据收集:这些问题出现在数据收集阶段,而且很难更正。它们被分为四个种类:
- 完全随机缺失:在这种情况下,缺失变量的发生概率和所有观测值发生的概率相同。例如:数据收集过程中受访者通过掷硬币来决定是否告诉数据收集者自己的收入。如果是正面就告诉,反之则不告诉。在这种情况下每个受访者都有同等的概率成为数据收集过程中的缺失值。
- 随机缺失:在这个过程中,变量是随机缺失的,缺失变量发生的概率也和其他变量发生的概率不同。简单说就是缺失值产生的原因不固定,不可追溯。
- 依赖于不可观测变量的缺失值:在这种情况下,缺失值是不随机的,并且和不可观测变量相关。不可观测变量就是现有的数据收集手段无法收集到这个变量值。
- 依赖于缺失值本身的缺失值:在这种情况下,缺失值的概率直接和缺失值本身相关。例如:在问卷调查中有较高或较低收入的人可能会不回应他们的收入。
有哪些方法处理缺失值?
- 删除:这里有两种:成列删除(个案删除)和成对删除。
- 在成列删除中,成列是全部变量都包括的意思,即当某个变量中的一项存在缺失值时,其他变量的相关项也全部删除。这种方法的优点就是操作简单,缺点就是减少了数据项,可能会减弱训练模型的效果。
- 在成对删除中,成对的意思是只包括你要分析的变量,而不是全部的变量。即当你要分析的某个变量中存在缺失值时,不是将所有变量的相关项删除,而是只删除你要分析的变量中的相关项。这种方法的缺点是会产生不同大小的数据样本,优点是尽可能多的保存了数据。
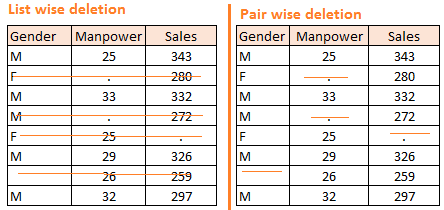
- 这种方法通常用于完全随机缺失值中,如果用于非随机缺失值则可能会使分析结果产生偏差。
- 均值、众数、中位数替换:替换是用估计值添补缺失值得一种方法。目标是利用已知的关系(即能被数据集中有效的值定义)来协助估计缺失值。 均值、众数、中位数替换是最常用的一种方法。它包含替换缺失值通过一个给定的属性(变量所有已知值的均值、中位数(定量属性)、众数(定量属性))。它有两种:
- 广义替换:在这种情况下,我们计算变量所有非缺失值的均值或中位数,然后用均值或中位数替换。在上面的表中,变量“Manpower”是缺失的,所以我们计算“Manpower”非缺失值的均值(28.33),然后替换它。
- 相似例子替换:即寻找和包含缺失值的项相似的例子,比如在其他某个分类变量下具有相同类别的项,然后再用这些项中的均值去替换缺失值。在这个情况中,我们分别计算性别“Male”(29.75)和“Female”(25)的均值,然后我们用 29.75 替换“Manpower”中“Male”缺失的值,用 25 替换“Manpower” 中“Female”缺失的值。
- 预测模型:预测模型是处理缺失值的一种复杂模型。在这里,我们创建一个预测模型去估值,然后用来替换缺失值。在这种情况下,我们将数据集分成两个数据集:一个数据集没有缺失值,另一个数据集有缺失值。没有缺失值的数据集作为模型的训练集,含有缺失值的数据集作为当做测试集,含有缺失值的变量作为目标变量。下一步,我们基于训练集其他属性创建一个模型去预测目标变量,然后填充测试集中的训练集。我们可以使用回归、方差、逻辑回归等各种模型来进行分析。这种方法有两个缺点:
- 这个模型估计的值通常比真值表现的更好。
- 如果数据集中的属性不相关,并且属性中含有缺失值,那么这个模型估计的缺失值是不精确的。
- KNN 替换:在这种替换方法中,用和含有缺失值属性最相似的属性来估算含有缺失值属性的缺失值。两个属性的缺失值可以用距离函数来计算。下面是已知的优点和缺点:
- 优点:
- K 临近算法能够预测定性和定量属性
- 不需要为每个含有缺失值得属性单独创建模型
- 含有多个缺失值的属性也能够被轻易处理
- 考虑到了数据的相关结构
- 缺点:
- 对于大数据 knn 模型是非常耗时的。它遍历所有的数据集寻找最相似的实例。
- K 值得选择是非常严格的。K 值过高会导致模型选择的属性和我们所需的属性显著的不同,k 值过低则意味着缺少显著的属性。
- 优点:
在处理了缺失值后,下一个任务是处理异常值。通常,在建立模型的时候我们倾向于忽视缺失值,这种行为是不鼓励的。缺失值会使你的数据倾斜并且减弱精确度.下面让我们学习异常值处理。
异常值处理
什么是异常值?
异常值通常是数据分析中的术语,并且是数据科学家需要注意的指标之一,因为它能导致完全错误的估计结果。简单的说,异常值就是偏离样本整体数据的值.举个例子:我们做客户分析,发现客户的年平均收入为 80万美金。但是这边有两个客户的年平均收入分别为 4 百万美金和 4.2 百万美金。 这两个客户的年平均收入远远高于样本中的其他人。这两个观测值可以看做是异常值。
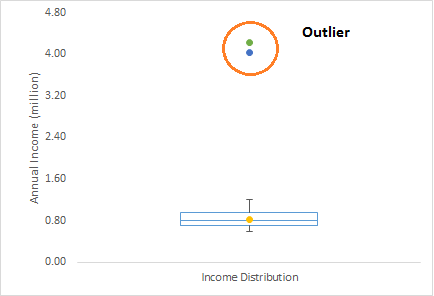
异常值有哪些类型?
异常值有两种:单变量和多变量。上面我们讨论了单变量异常值的例子。这些异常值是被发现在单个变量的样本分布中。多变量异常值出现在 n 维空间为了发现多变量异常值,你需要在多维空间中查看样本的分布情况。 让我们通过下面的例子理解异常值。我们尝试去理解 weight 和 height 之间的关系,下面是 height 和 weight 的单变量和双变量样本分布。 首先看箱型图(单变量分析),我们没有任何的异常值(大于上四分位数加 1.5 倍四分位距或小于下四分位数减 1.5 倍四分位距)。然后我们看散点图,这里有一个值明显高于 weight 和 height 的区段的均值,一个值明显低于 weight 和 height 的区段的均值。
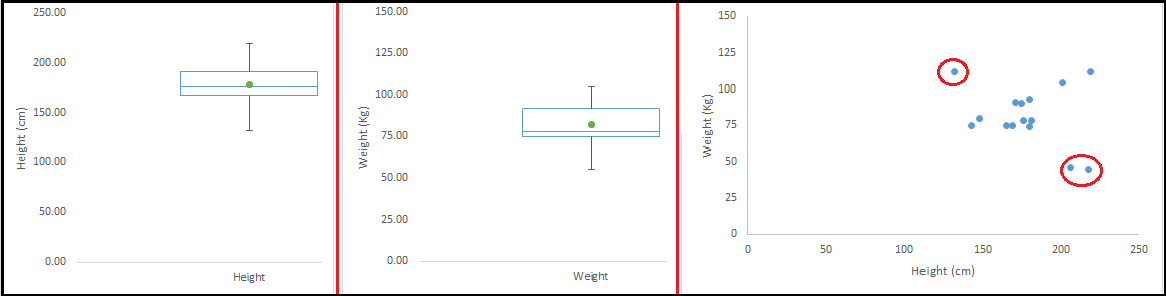
注:这里有一篇高维数据异常值检测的方法
什么造成异常值?
无论什么时候遇到异常值,处理他们最理想的方式是找到这些异常值出现的原因。处理异常值的方法取决于异常值出现的原因。引起异常值的原因能分为两大类:
- 人工造成的/非自然
- 自然造成的
下面是几种异常值种类的细节描述:
- 数据输入错误:人工在数据收集、记录、输入造成的错误,可能会成为数据中的异常值。例如:一个客户的年均收入是 10 万美金,但是数据记录员在输入的时候不小心多加了 一个 0,现在年均收入是实际的十倍。明显的,这个数据在和样本其他数据比较时将会变成异常值。
- 测量误差:这是最普遍的异常值来源。这个原因是当你使用了错误的测量仪器时造成的。例如:这里有 10 台测重器,其中 9 台正确,一台错误。用了错误测重器的人, 体重会比同组的其他人高或低。这个错误的测重器导致出现了异常值。
- 实验误差:实验误差也是造成异常值的原因。例如:在 100米冲刺中的七名运动员,一位运动员在起跑的时候落后了(裁判喊跑后,运动员隔了些时间才反应过来)。 因此,这个造成起跑落后的运动员比其他运动员跑完 100m 的时间长。起跑落后的运动员 100m花费的时间可能会成为异常值。
- 故意离群:这个通常是在自我报告中涉及敏感数据时造成的。例如:青少年在报告他们的饮酒量时,只有一部分人会报告真实的数据。
在这里由于大部分青少年的虚假数据,小部分真实的数据可能会成为异常值。 - 数据处理错误:当进行数据挖掘时,我们从多个数据源获取数据。一些操作或提取错误(sql 语句错误)可能会导致数据集中出现异常值。
- 抽样误差:例如,我们计算运动的身高时,错误的抽取了篮球运动员作为样本中的一部分,这会使数据集中出现异常值。
- 自然异常值:当异常值出现的原因不是人工造成的,我们说它是自然异常值。例如:在作者的上一个任务对一家著名的保险公司进行分析时,作者注意到前 50 名财务顾问的
表现远远高于其他人。令人惊讶的是它不是由任何错误造成的。因此当对这些财务顾问做数据挖掘时,我们需要对这些人区别对待。
异常值对数据集会造成哪些影响?
异常值可以极大地改变数据分析和统计模型的结果。数据集中的异常值有许多不利的影响:
- 它增加了误差方差,降低了统计检验的效果
- 如果异常值是非随机分布,它们可能会减弱样本的正态性。
- 它们会使估计值产生偏差。
- 它们也会影响基本的回归假设、方差分析和其他统计模型假设。
下面是一个例子:
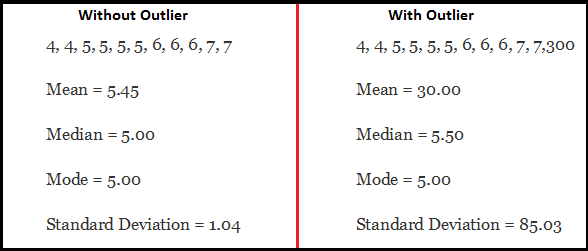
例子中包含异常值的数据中,均值和标准差都明显大于无异常值数据中的均值和标准差。
异常值的存在完全改变了评估结果。
如何检测异常值?
可视化是检验异常值最常用的一种方法,例如箱型图、直方图、散点图。一些分析师也使用经验法则检测异常值。
- 将大于上四分位数加 1.5 倍四分位距或小于下四分位数减 1.5 倍四分位距的数据当做异常值;
- 使用覆盖的方法,将所有不在 5%到 95%范围的值当做异常值;
- 偏离平均值三个或以上标准偏差的数据点;
- 异常值检测只是检测大影响力数据点的一种特殊情况,具体的操作往往也依赖于具体的业务模式;
- 单变量或多变量异常值通常是用影响因子、水平因子、距离因子中的某一个指标来度量的。Mahalanobis’distance 和 Cook’s D 是目前比较常用的检测异常值得方法。
- 在 SAS 中, 可以使用 PROC Univariate、PROC SGPLOT、STUDENT COOKD RSTUDEBT.
怎样去除异常值?
处理异常值得手段和处理缺失值的手段是相似的,例如删除观测值、转换、合并、分组对待、替换或其他统计方法。在这,我们主要讨论最常用的方法。
删除异常值:如果异常值是由于数据输入错误、数据处理错误或异常值数目很少,我们可以删除它们。我们可以通过修剪两端删除异常值。
数据转换或聚类:( binning ):转换数据也可以剔除异常值,例如对数据取对数可以减少极端值的变化。我们也可以用决策树直接处理带有异常值的数据(决策树基本不会受到异常值和缺失值的影响),或是对不同的观测值分配权重。
![]()
替换:类似替换缺失值,我们也可以替换异常值。我们可以使用均值、中位数、众数替换方法。但是在替换之前,我们首先要分析它是人工造成的还是自然造成的。如果是人工造成的,我们可以替换它。同时我们也可以用统计模型预测异常值,然后替换它。
分离对待:如果异常值的数目比较多,在统计模型中我们应该对它们分别处理。一个处理方法是异常值一组,正常值一组,然后分别建立模型,最后对结果进行合并。
到这里,我们已经学习了数据探索、缺失值处理、异常值检测和处理。这三个步骤将使你的数据具有更好的信息可用性和准确度。下面我们将学习特征工程。
特征工程的艺术
什么是特征工程?
特征工程是从现有的数据中提取出更多信息的一门科学,你不需要添加新的数据,但确能让你的数据展现更多的信息。
例如,让你基于数据预测商场中顾客的足迹。如果你直接使用数据分析可能不能得到有用的见解。这是因为一周里某天顾客的足迹信息比一个月里某天的足迹信息能够展现更多的信息。现在这个关于每周里某天的信息是隐藏的。你需要把它找出来,以此让你的模型更好。(涉及到了数据的分辨率问题)。特征工程就是从已知的数据中找出有用信息的过程。
特征工程的过程是什么?
当你完成前 5 个步骤时可以进行特征过程-变量定义、单变量分析、双变量分析、缺失值替换、异常值处理。特征工特可以分为以下两步:
- 变量转换
- 变量/特征创建
以上两步是数据探索中非常重要的两个技术,并且对预测的效果有一个显著的影响。下面让我们从细节上理解这两步。
什么是变量转换?
在数据建模中,转换是指通过一个函数对变量进行替换。例如,对变量 x 施加平方、平方根、取对数等函数是一个转换。
换句话说,转换是通过其他手段改变一个变量的分布或关系的进程。
下面让我们看一下什么场景下变量转换是需要的。
什么时候我该使用变量转换?
下面是需要使用变量转换的场景:
- 当需要改变变量的比例或对变量进行标准化处理时需要使用变量转换。例如变量间的单位都不相同,这时可以对变量进行归一化处理,去除单位的影响。
- 当需要将非线性关系转换为线性关系时需要使用变量转换。例如当我们对数据建立线性回归模型时,如果发现回归图(理解回归图是能更好的应用线性回归)呈现出非线性关系,可以对自变量进行非线性转换(取对数,取平方根等)。
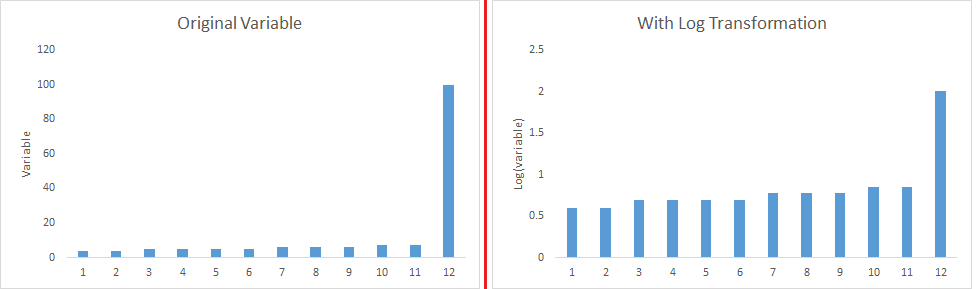
散点图能够被用来发现两个连续变量间的关系。这些转换也可以提高预测效果。对数转换是最常用一种方法。
-
对称分布是优于偏态分布的,因为对称分布更容易解释和得出推断。一些建模技术是要求变量是正态分布的。我们可以使用转换减弱倾斜。
对于右偏态分布,我们可以对变量取平方、平方根、对数。对于左偏态分布,我们可以对变量取平方、平方根、指数。
- 变量转换也可以从实施角度(人工干预)来做。让我们理解的更清楚些,在作者员工绩效的一个项目中,作者发现年龄与员工的绩效有直接关系,例如年龄越高,表现越好。
从实施的角度,开展基于年龄的计划可能实现的挑战。但是,将代理销售按年龄分为三组:<30,30-45,>45,然后对每一组制定不同的策划是一个明智的方法。 聚类 or 决策树是一个众所周知的分类方法。
变量转换最常用的方法是什么?
这里有各种方法用于变量转换。我们已经讨论过对变量取平方、立方、对数、装箱、倒数等其他方法。下面让我们看一下这些方法的优点和缺点。
- 对数:取对数是改变变量分布的最常用的变量转换方法。它一般用来减弱变量的右倾斜。但是,它不适用于变量中存在 0 或负值的情况。
- 平方或立方:对变量取平方或立方根对变量的分布有显著的影响。但是,它不如对数转换显著。立方根有它自己的优势。立方根能被用在变量存在 0 或负值的情况。平方根能被用来变量为正值且包含 0 的情况。
- Binning :它被用来变量分组。它可以被用在原值、百分数或频数上。分类技术的决策是基于业务的理解。例如,我们可以对收入分为三类:高、中、低。同时我们也可以对多个变量一起分组,例如收入和年龄两个变量,低龄高收入可以当作富二代群体,低龄低收入当作贫二代群体(只是举例而已)等等。
什么是特征创建?它的优点是什么?
变量创建是根据现有变量创建新变量的过程。例如,在数据集我们将 date(dd-mm-yy)作为输入变量。我们能生产新变量,例如天(dd)、月(mm)、年(yy)、周、周日等更好的表现与目标变量关系的新变量。下面高亮的部分就是一个变量(date)中隐藏的关系。

这里有几种方法用于创建新特征,下面是最常用的几种方法:
- 创建派生变量:对现有的一个或多个变量实施一个函数来创建新的特征。特征的创建一般需要数据使用者对业务极其了解并经过多次假设验证才能得到一个不错的特征。我们通过这个数据集理解如何创建派生变量。在这个数据集中,变量存在缺失值。为了预测缺失值,我们使用称呼(Master, Mr, Miss, Mrs)作为新变量。我们如何决定哪个变量该创建?说实话,这依据于分析师关于讨论问题中对业务的理解、好奇心以及一系列的假设。像取对数、binning variables或其他变量转换方法也可以用来创建新变量。
- 创建虚拟变量:最常用的创建虚拟变量的方法是将分类变量转换为数值变量。虚拟变量也被成为指示变量。在统计模型,它通常被用来将分类变量当做一个预测指标。分类变量可以设值为 0 和 1。我们可以将“gender”变量分为两个变量“Var—Male”和“Var—Female”,如果 Var-Male 为 1 则为 Male,为 0 则为非 Male。Var-Female 同理。
我们也可以将一个分类变量里的多个类别创建为多个虚拟变量。
